 VIGIL
VIGIL
Part-Centric Structured Forensic Framework
†Corresponding Author

Analyze whether this image is authentic (Real) or AI-generated (Fake).
Experience VIGIL's structured forensic reasoning with reasoning reversion — where accumulated part-level evidence overturns an initially incorrect judgment.
Multimodal large language models (MLLMs) offer a promising path toward interpretable deepfake detection by generating textual explanations. However, the reasoning process of current MLLM-based methods combines evidence generation and manipulation localization into a unified step. This combination blurs the boundary between faithful observations and hallucinated explanations, leading to unreliable conclusions. Building on this, we present VIGIL, a part-centric structured forensic framework inspired by expert forensic practice through a plan-then-examine pipeline: the model first plans which facial parts warrant inspection based on global visual cues, then examines each part with independently sourced forensic evidence. A stage-gated injection mechanism delivers part-level forensic evidence only during examination, ensuring that part selection remains driven by the model's own perception rather than biased by external signals. We further propose a progressive three-stage training paradigm whose reinforcement learning stage employs part-aware rewards to enforce anatomical validity and evidence–conclusion coherence. To enable rigorous generalizability evaluation, we construct OmniFake, a hierarchical 5-Level benchmark where the model, trained on only three foundational generators, is progressively tested up to in-the-wild social-media data. Extensive experiments demonstrate that VIGIL consistently outperforms both expert detectors and concurrent MLLM-based methods across all generalizability levels.
Our key observation is that forensic reasoning over facial images is naturally part-localized — forgery traces concentrate in specific anatomical regions and vary across generation methods. Inspired by expert forensic practice, VIGIL adopts a plan-then-examine pipeline:
The model observes global visual cues and autonomously selects which facial parts to inspect — without exposure to any external forensic signal.
A stage-gated mechanism injects frequency-domain and pixel-level features as part-level evidence embeddings, providing each selected region with independently sourced forensic support.
Part-level findings are synthesized into a final verdict. Accumulated evidence can overturn an initially incorrect judgment — a capability we call reasoning reversion.
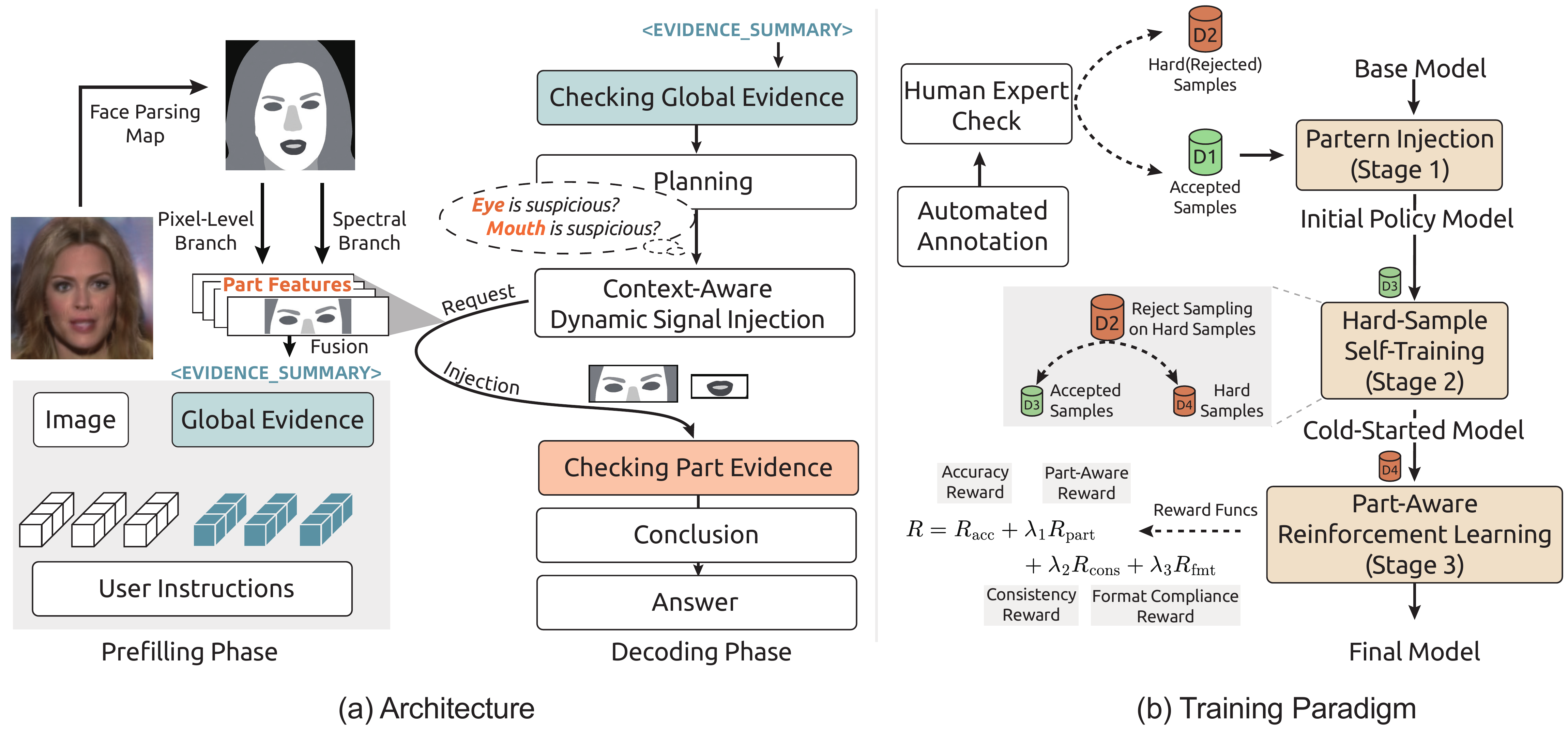
Figure 1. Overview of VIGIL. The model first plans which facial parts to inspect based on global cues, then examines each part with independently sourced forensic evidence delivered via context-aware dynamic signal injection. A progressive three-stage training paradigm (SFT, hard-sample self-training via rejection sampling, and RL with part-aware & evidence-conclusion consistency rewards) ensures genuine evidence reasoning rather than template memorization.
OmniFake is a hierarchical 5-Level benchmark containing over 200K images designed for fine-grained generalizability evaluation.
The model is trained on only three foundational generators and progressively tested across increasingly challenging levels.
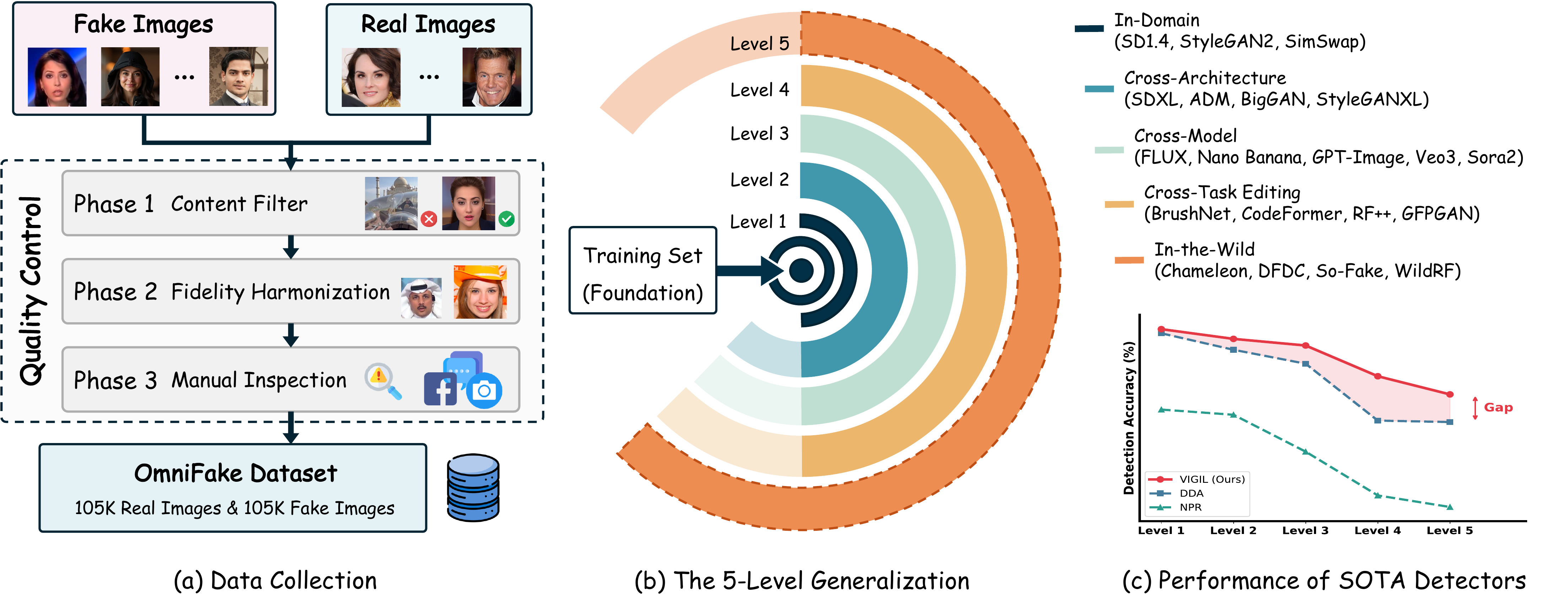
Figure 2. Overview of the OmniFake dataset. (a) Data collection and quality control pipeline. (b) The hierarchical 5-Level generalization protocol. (c) Performance of existing detectors across levels, showing a widening generalization gap at higher levels.
VIGIL consistently outperforms both expert detectors and concurrent MLLM-based methods across all OmniFake levels.
| Method | L1 | L2 | L3 | L4 | L5 | Avg. |
|---|---|---|---|---|---|---|
| AIDE ICLR'25 | 72.3 | 89.1 | 81.6 | 67.6 | 75.0 | 78.9 |
| Co-SPY CVPR'25 | 83.5 | 89.9 | 89.0 | 71.3 | 82.5 | 84.7 |
| DDA NeurIPS'25 | 97.8 | 94.6 | 91.9 | 81.0 | 80.7 | 88.8 |
| GPT-5.2 | 65.8 | 82.7 | 73.6 | 58.8 | 69.0 | 71.4 |
| Gemini-3-Pro | 72.3 | 85.9 | 78.5 | 61.0 | 69.9 | 75.0 |
| FakeVLM NeurIPS'25 | 83.5 | 81.0 | 76.8 | 74.5 | 74.9 | 77.1 |
| Veritas ICLR'26 | 96.8 | 94.9 | 89.9 | 79.0 | 81.1 | 87.6 |
| VIGIL (Ours) | 98.6 | 96.7 | 95.5 | 89.5 | 86.0 | 93.1 |
Accuracy (%) on OmniFake. L1: In-Domain · L2: Cross-Architecture · L3: Cross-Model · L4: Cross-Task · L5: In-the-Wild
Bold = best, underline = second best.
If you find our work useful, please consider citing:
@article{li2026vigil,
title={VIGIL: Part-Grounded Structured Reasoning for Generalizable Deepfake Detection},
author={Li, Xinghan and Xu, Junhao and Chen, Jingjing},
journal={arXiv preprint arXiv:2603.21526},
year={2026}
}